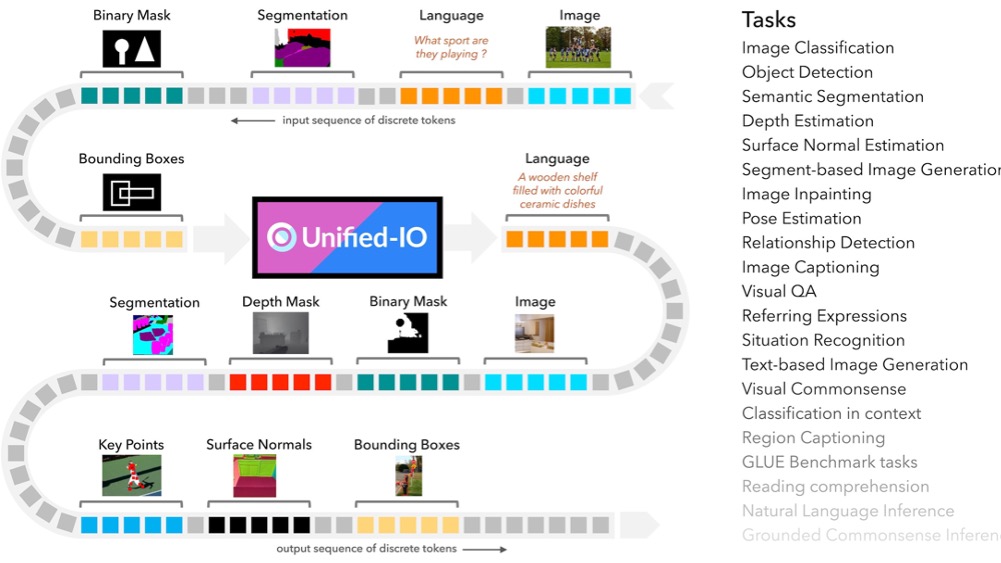
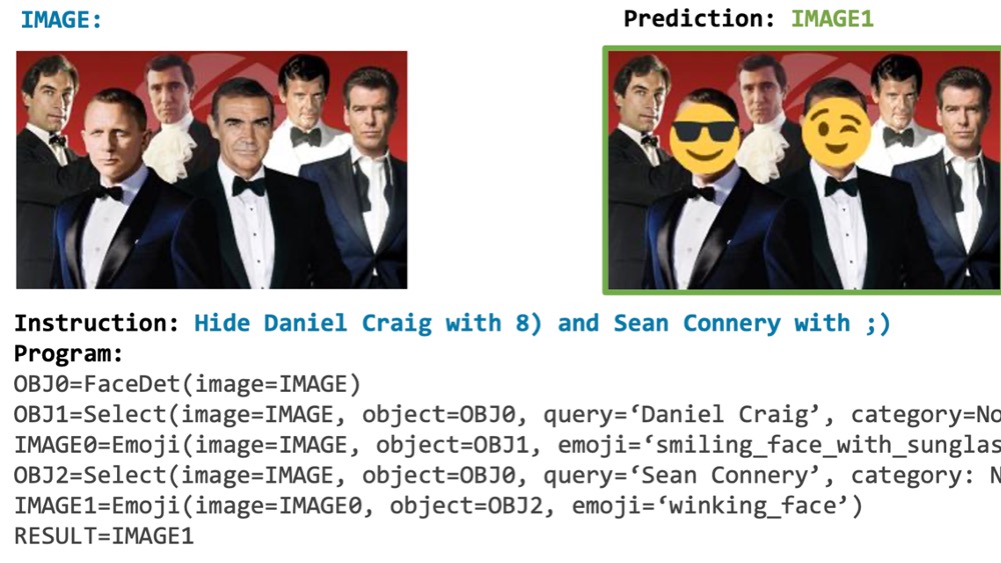
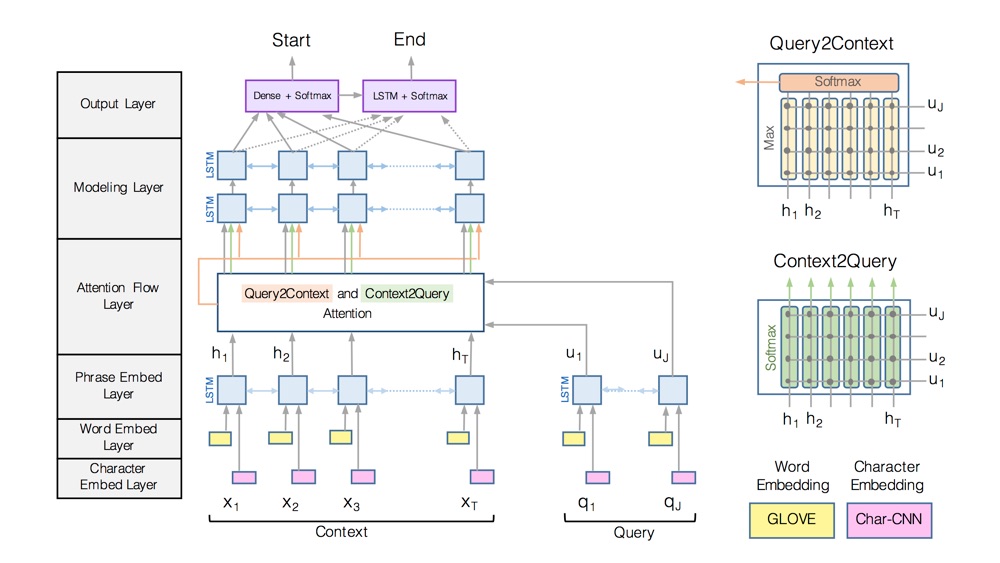
I am an AI Researcher at Meta Superintelligence Labs building frontier multimodal models.
I was a Director at Wayve AI in London, UK building world models for autonomous driving. Before that, I spent 10 years at the Allen Institute for AI (AI2) in Seattle. I was the Senior Director of Computer vision, leading research teams focussed on Multimodal AI and Embodied AI.
Our research won several Best and Outstanding paper awards at CVPR, Neurips, CoRL, ICRA and more!
I am also an Affiliate Associate Professor at the Computer Science & Engineering department at the University of Washington.
I enjoy building and deploying AI applications for users to interact with. My work over two decades spans computer vision, robotics and natural language processing.
I got my Ph.D. at the University of Maryand, College Park under Prof. Larry S. Davis, and also spent five years at Microsoft working in Image and Video Search.
Google Scholar